前言
其实, 本文更应该写成一篇2016年工作总结的, 无奈, 精神拖延, 身体懒惰, 迟迟未能着手. 恰逢周末, 遂总结下自己工作以来的一些经验和看法, 因为这几年一直做大数据系统的开发, 就勉强起名–我的”大数据项目架构概述”.
架构图
以下就是我们在项目实践中, 践行的一套架构. 当然, 不同的项目系统根据需求的不同, 架构模块也会有所不同.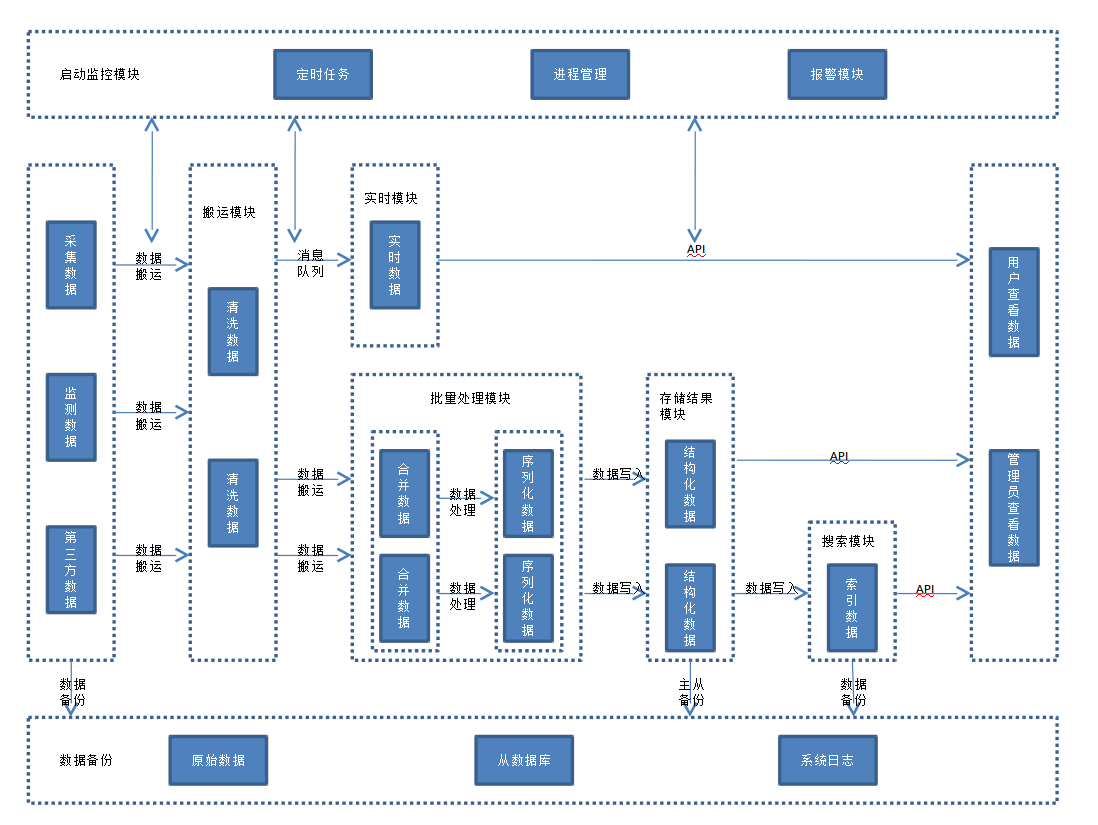
大体分以下个模块.
- 数据采集模块
- 数据搬运模块
- 大数据处理模块- $\lambda$ 架构
- 数据存储模块
- 搜索模块
- 前后端分离
- Web 框架
模块解析
下面就对每一个模块进行简要介绍和分析.
数据采集模块
数据采集的内容包括采集数据, 监测数据, 第三方数据, 客户自有数据.
采集数据
采集数据主要通过爬虫, API来获取. 这两种方式各有优劣:
爬虫需要自己开发, 或在现有的爬虫框架下开发, 需要的工程量比较大, 包括抓取策略, 更新策略, 模拟登录, 频次控制, 代理设置等等, 还要时刻应对对方的反爬做出及时响应, 如果对方需要登录, 那就需要更多的爬虫帐号.
大的网站, 为了真实用户更好的体验, 也为了建立生态, 会开放API接口, 供需要数据的需求方获取数据, 这个就不太需要考虑被封, 但是, 这种方式获取的数据的范围和数据完整程度较爬虫就有一定缺失了.
总之, 我们需要根据自己的需求和成本, 适当权衡.
监测数据
像我司就是做第三方监测的, 就需要对需要监测的网站或网页或物料加监测代码, 当用户浏览网页或触发事件时候, 就会发送监测日志到指定服务器, 以便完成监测的目的. 因为要对接的网站, 网页千奇百怪, 为了保证数据的完整性,有效性, 所以做前期的测试就十分必要了.
那测试什么呢? 我们给对方代码及文档, 告诉他们在什么地方, 放置什么代码, 这些需要对应有一定的代码能力. 对方完成后, 就是要看能否收到日志, 字段是否完整, 事件能否被触发.
数据可以使用 ligttpd, Nginx 打印日志到文件或系统.
第三方数据
这里定义的第三方数据, 是针对系统开发公司说的, 包括通过数据交易平台, 与其他公司交易/交换等方式获取的原始的, 或 ETL 后的数据.
比如我们需要一个全网数据的统计模块, 但这个模块在我们的系统中是非核心的, 自己开发一套类似搜索引擎的爬虫系统, 就得不偿失了. 快速靠谱的方式, 就是以合理的成本, 在市场上找一个靠谱的服务提供商, 毕竟术业有专攻. 这方面的教训, 就是一定不要图便宜, 而是要通过调研, 找到性价比最好的那个. 否则, 在钱上的吝啬, 一定会以时间的慷慨作为代价弥补上的.
客户数据
大部分公司都会有自己的私有数据, 类型多种多样, doc, pdf, 数据库等等. 这部分数据需要做好数据安全性, 大部分 Inhouse 项目也是做此考虑. 如果数据一定要对接到外部系统, 一定做好数据的脱敏.
客户数据对接, 一个比较大的挑战应该是数据ETL, 数据不同, 提供定制化的开发, 同时, 针对每个公司的对接系统通常不能复用, 做这部分, 需要很大的耐心和细心.
数据搬运模块
数据通过各个方式采集, 到存储系统加以使用前, 通常需要对数据做进一步的处理, 包括数据搬运, 数据清理, 数据合并, 数据格式化.
我司主要使用的是自己开发的搬运流系统, 主要完成日志合并,简单处理和分发.
我了解到的类似框架, 包括 Flume, Logstash 等, 并使用过 Logstash 做数据搬运流, 相比 Flume, Logstash 本身更轻量些, input->filter -> output 的管道化, 加上各种适配插件, Logstash 能让数据搬运更加方便.
大数据处理模块- $\lambda$ 架构
一般的大数据系统, 都是采用 $\lambda$ 架构, 网上有很多这方面的文章介绍, 我就不班门弄斧了. 主要由实时数据模块和批量处理模块组成, 因为这两个模块在需要解决的问题, 处理的数据量, 处理速度等方面大不相同, 也决定了底层设计的差异.
批量处理模块
10多年来, Hadoop 一直是主流的大数据框架, 并在它基础上出现了许多优秀的框架. 现在, 随着其他框架如雨后春笋一般, Hadoop 更多地以 HDFS 存储被使用. 而 HDFS 以 block 为存储单位, 一般大小为 64M, 所以最好不要存储小文件, 而是将小文件进行合并, 生成大的压缩文件, 组合文件或序列化文件, Hadoop 平台的进一步 ETL 就有必要了.
Spark 基于内存计算, 比 Hadoop 有更好的性能. 在迭代计算上, 优势更明显, 还有丰富的机器学习模型. 但是, action 会做集群内数据的 shuffle, 所以, 多用 transformation, 少用 action, 并进行参数调优, 就能体验飞的感觉.
我们现在在大数据计算上, 通常是 Hadoop 和 Spark 二选一.
实时模块
虽然叫做实时, 但流式框架其实更符合它, 主流的大数据框架, 包括 Storm, Spark Streaming 等. 其实, Elasticsearch 也是可以做到实时处理数据的.
Storm 使用用于实时计算的 topology, 一个 topology 使用 spout 发送消息, 使用 bolt 完成计算过滤.
Spark Streaming 按照预先时间窗口对数据批量处理, 可以做到秒级准实时.
初期, 数据量不大可以用 Redis, Memcached 等内存数据库, 主要是上手快.
数据分发可以用 Kafka 等框架, 但是, 对于我们太重, 就直接写 生产者/消费者 模型, 完成实时模块数据流.
数据存储模块
批量处理的结构化数据, 一般我们会存储到 MySQL, PostgreSQL 等数据库.
我们部门的技术栈是前者, 因为 MySQL 是最成熟的开源数据库, 能满足我们的需求, 而且我们也对 MySQL 最熟悉.
数据库架构包括主从备份, 读写分离, 两者都需要注意的是数据一致性, 可以参见翻译文章 MySQL主从一致介绍.
数据库设计, 注意设计范式和反设计范式之间的选择, 后端 API 的设计可用性也要考虑在内.
性能优化时候, 考虑建立索引, 分表分区等手段.
搜索模块
通常的系统, 都会包含搜索功能, 数据量小时候, 像MySQL 中可以用 like %% 来解决 , 但像数据达到亿级别时候, 再用 like %% 就不能满足需求了.
这时, 我们将注意力转向 Elasticsearch. 它本质是分布式的搜索引擎, 我之前做过一次公司的技术分享, 后续会更新文档做介绍, 如果是首次使用, 建议直接使用最新的 Elastic Stack 5+, 性能较前面版本有较大提升.
前后端分离
我们完成前后端分离, 项目解耦合, 通过提供 REST 的API 对外吐数据. 这方面的技术栈, 主要是
- Java: SpringBoot
- Python: Flask, Torando
系统开发过程中, 需要做好权限控制, 缓存机制, 防止 SQL 注入, 接口测试等等.
Web 框架
这个是真不懂了, 每次做项目, 前端工程师总能尝试新的框架, 而我还在认真地写 MapReduce.
其他
定时任务多以 crontab, 任务队列使用 beanstalk, 进程管理使用 supervisor.
问题
上面的数据处理模块和存储模块, 在处理数据多维钻取上, 特别像 20+ 维度的pv/uv 自由组合计算, 就有些力不从心. 这时就需要考虑其他的框架, 比如 HBase, Druid, Kylin 等就是不错的选择, 系统设计就是另外一番场景了.
总结
洋洋洒洒数千字, 回头看, 每个模块有所涉猎, 但又不能全部知其然, 并知其所以然. 取名大数据项目架构概论, 但每个都没有详细展开, 诚惶诚恐, 恐贻笑大方. 以后, 还需各方面打磨, 以期下次总结, 能在一两个模块上深入展开.
为者常成, 行者常至.